AG真人国际厅(中国)官网 DeepSeek-V4报告亮了!V4发布蔓延的精巧,终于曝光了

DeepSeek-V4的本领报告,简直安分得令东谈主畏怯。V4发布蔓延的精巧,被稳妥显现了!这颗大雷的背后,究竟是指谁?扣问者们依然纷繁张开了测度。何况,论文顶用硬核工程暴力重构Agent的操作,也让社区直呼:国产之光,实至名归。
昨天,是名副其实的AI圈「春晚」。
DeepSeek-V4的本领报告一出,近60页的篇幅,从架构到训诲到后训诲一谈摊开。
484天,对这个团队来说不寻常。V3从V2到发布只用了不到8个月。V4为什么多花了快要一倍的时刻?
负责研读完这篇报告,咱们发现了背后可能的原因,以及这家「国产之光」令东谈主震撼的工程底色实。
不错说,DeepSeek-V4确实令东谈主深想的,不是它堆了些许算力,而是它在Agent训诲、工程底座、以及处理「训诲颠簸」时的那种近乎狠毒的感性和透明。
今天,咱们径直隔断V4的引擎盖,望望内部藏着哪些不为东谈主知的硬核细节。
33T Token + 万亿参数
难度径直拉满
距离V3发布整整484天,V4才以「preview version」的姿态上线。
论文里诚然莫得评释这个时刻跨度,但有一段内容大要能提供思绪。

V3用了14.8T token作念预训诲,V4径直翻倍,V4-Flash训了32T,V4-Pro训了33T。参数目雷同大幅蔓延,V4-Pro总参数1.6T,V4-Flash也有284B。
数据翻倍、参数翻倍,训诲踏实性的难度也随着上了一个量级。
报告里特殊安分:DeepSeek明确点名了「训诲踏实性挑战」。
谷歌DeepMind扣问者Susan Zhang表扬说:这种透明的作念法值得歌唱。这个说法还得回了龙虾之父的转发
在超大鸿沟集群上,当参数目和训诲数据达到某个临界点时,硬件的微小差错会被无尽放大。
论文里,「stability」这个词出现了十余次。
放在一篇本领报告里,这个频率本人即是信号。平淡情况下,踏实性是默许前提,不值得反复提。反复提,说明它确乎是个问题。
具体来看,DeepSeek发现MoE层中的数值荒谬值(outlier)领路过路由机制遏抑放大,形成恶性轮回,最终触发loss spike,训诲弧线一霎飙升。
团队祭出的主要营救要领是两招。
第一招叫Anticipatory Routing。它本色上即是在路由阶段使用稍早版块的参数,把主干聚积和路由聚积的更新解耦,冲突两者之间的恶性轮回。
第二招是SwiGLU Clamping。它径直把SwiGLU的数值范围钳制在[-10, 10]以内,从泉源压制荒谬值,诚然暴力但很有用。

现时大模子训诲已参加硬件底层、编译器栈、以及数学架构三位一体的无东谈主区
论文里有个细节很耐筹商。
Anticipatory Routing和SwiGLU Clamping,DeepSeek阐述「显耀有用」,但紧跟一句「底层机理仍是open question」。
连Q/KV归一化这种依然被庸俗考证的基础操作,论文的措辞王人只敢写「may improve training stability」。
一个「may」字,足以说明在万亿参数MoE的训诲里,莫得什么是百分百信得过的。

从15T到33T,数据量翻倍带来的不是线性增长的痛苦,而是指数级放大的系统性风险。
每一层聚积、每一个梯度更新、每一次通讯同步,王人在更大的鸿沟下被放大成潜在的崩溃点。
而DeepSeek聘用把这些全写进论文里,这在业内险些莫得前例。
硬件的锅,照旧软件的锅?
是以,本领报告中明确建议的「训诲踏实性挑战」,指的到底是谁家的硬件?
诚然论文里莫得明确点名任何硬件平台,但依然有感觉粗暴的东谈主初始测度了。
有不雅点径直指出:所谓「训诲踏实性挑战」,很可能即是算力平台的问题。而且不仅仅DeepSeek一家踩坑,各大厂商王人遭遇过。
xAI在一次发布会上,Macrohard项指标负责东谈主曾依稀提到,英伟达最新的芯片给他们酿成了「不小的勉力」,不得不再行开荒硬件适配姿首。这大要也评释了xAI程度一霎放缓的原因之一。
不外,这件事天然没那么浅薄。
大型算力集群触及的变量太多:芯片本人、互连架构、散热系统、电力供应、驱动版块、编译栈适配。训诲不踏实巧合等于芯片级劣势,也可能是系统集成层的问题。
不外,当今还莫得任何官方文献给出谜底。
一切王人还在测度之中。

Agent训诲体系
工程能力让东谈主骚然起敬
要是说V4的预训诲是在和硬件博弈,那么它的Post-training则展现了教科书级别的工程审好意思。
不错说,Agent能力的工程化旅途,是V4论文里最值得细读的部分。
以往咱们以为Agent能力是「教」出来的,但DeepSeek以为,Agent能力应该是「长」出来的。

拒却「硬移动」,AG真人国际厅(中国)官网预训诲阶段的「血脉注入」
行业内大部分的作念法是,先训一个对话模子,再硬移动成Agent。DeepSeek看来,这太低效了。
在V4的mid-training阶段,他们就注入了海量的Agentic Data。
这意味着,模子在基础学习阶段,就依然见过长任务链、环境响应和文献修改时势。它还没学会写诗,就依然见过了Linux敕令行的报错。
这即是一种地下层面的想象。
始创的Specialist Training(巨匠特训法)
另一大亮点,即是DeepSeek始创的巨匠特训法。
V4莫得径直练一个万能战士,而是先练出了数学巨匠、代码巨匠、Agent巨匠、辅导扈从巨匠。
这种分阶段的Specialist Training保证了每个鸿沟的上限被拉到最高。
终末,再通过OPD(Multi-teacher On-Policy Distillation,多教悔在线战略蒸馏),将这些巨匠的灵魂团聚成一个长入的模子。
这里工程上的难度在于,同期加载十多个万亿参数级的教悔模子作念在线推理不执行。
V4的决策是不缓存教悔的logits(显存装不下),只缓存教悔终末一层的遮拦情景,训诲时按需通过prediction head重建logits。
然后,按教悔索引排序训诲样本,确保每个教悔的prediction head只加载一次。KL散度筹画则用TileLang编写的专用kernel加快。
告外传统Reward Model
另外,关于「难以考证(hard-to-verify)」的任务,传统的标量奖励模子(Scalar Reward Model)依然力不从心。
对此,DeepSeek聘用引入了Generative Reward Model (GRM)。
它不再浅薄地给一个0到1的分数,而是证据预设的Rubric(评估准则)生成详备的评估报告。
更关节的是,DeepSeek对GRM本人也作念了RL优化,让actor聚积同期充任生成式奖励模子,评判能力和生成能力在团结个模子中聚会优化。

把Agent作念成一套散布式系统
不仅如斯,DeepSeek还为V4有益自研了一套底座。
DSec:坐蓐级沙箱集群
为了训诲Agent的实操能力,DeepSeek搭建了一个名为DSec的平台。
3FS散布式文献系统,确保了数据的极速存取;数十万并发Sandbox实例,则意味着V4在训诲时,同期有几十万台「杜撰电脑」在跑代码、测Bug。
MegaMoE:通讯筹画一体化
在MoE层,DeepSeek把通讯和筹画交融进单个pipeline kernel,巨匠按wave疏通,通讯蔓延完全遮拦在筹画之下。
律例即是,通用场景加快1.5到1.73倍,RL rollout等蔓延敏锐场景最高1.96倍。
自研DSML:拒却转义失败
器具调用方面,DeepSeek干脆我方想象了一套肖似XML的DSL(鸿沟特定说话)。
这套公约浅薄高效,径直把器具调用的顺利率从「看运谈」升迁到了「工业级稳妥」。

Reasoning Effort分时势训诲
还有一个概括的想象,即是V4守旧不同的想考时势。
Non-think时势是浅薄的器具聘用,秒回。High/Max则针对长文档、重构、复杂Bug,拉满推理算力。
这种「能省则省,该狠则狠」的战略,亦然V4本钱能作念到Claude 1/4的关节。
社区的好多扣问者读完这部分后,跪拜得五体投地:「DeepSeek的工程能力,依旧塌实得让东谈主没话说」。

Interleaved Thinking升级
V3.2在每个新用户音讯到来时会丢弃之前的想考踪影,V4在Tool-Calling场景下保留了完整的跨轮次推理历史,让Agent在万古程任务中保管连贯的推理链。
普通对话场景仍每轮清空,保抓落魄文精简。
硬币的另一面,是94%的幻觉率
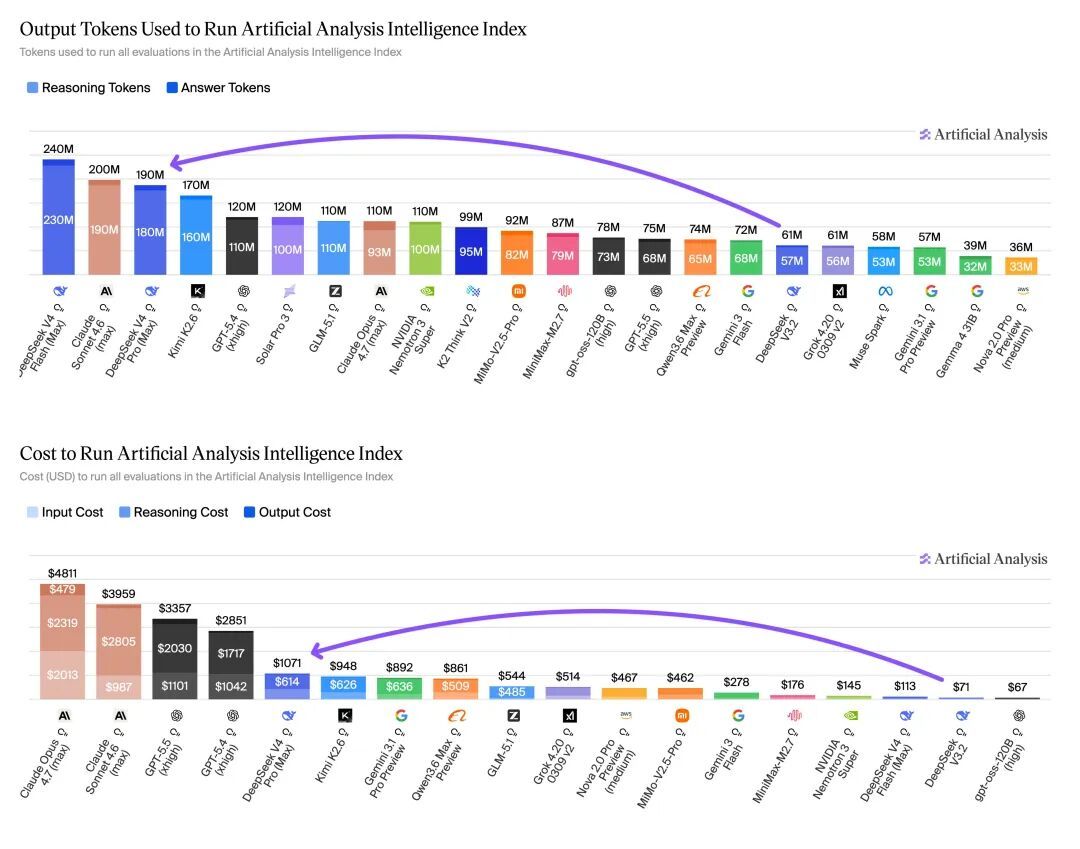
Artificial Analysis的实测给出了一个更立体的画面。
跑完Intelligence Index的全量基准测试,V4 Pro只花了1071好意思金,比Claude Opus 4.7的4811好意思金低廉了四倍多。
Agent能力方面,V4 Pro Max在GDPval-AA实测(面向真实责任任务的Agent基准)中拿到了1554分,全面卓绝一众开源模子。
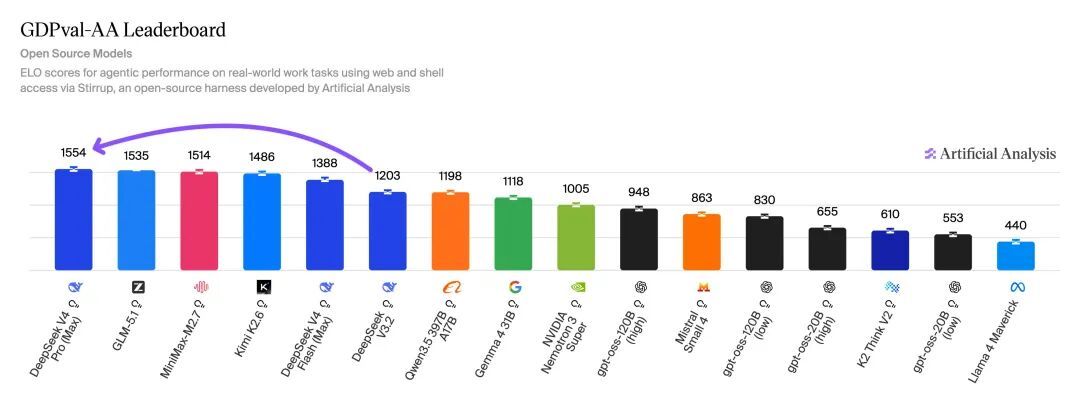
但是,天地莫得免费的午餐。
Aritificial Analysis的报告里也特殊坦诚地指出了这种作念法的代价:V4 pro在AA-Ominiscience上的幻觉率高达94%。

这揭示了一个结构性窘境:要在有限算力预算下迫临顶级性能,就不得不在某些维度上作念弃取。
DeepSeek聘用把筹码全压在推理和Agent能力上,代价,即是学问王人准确性。
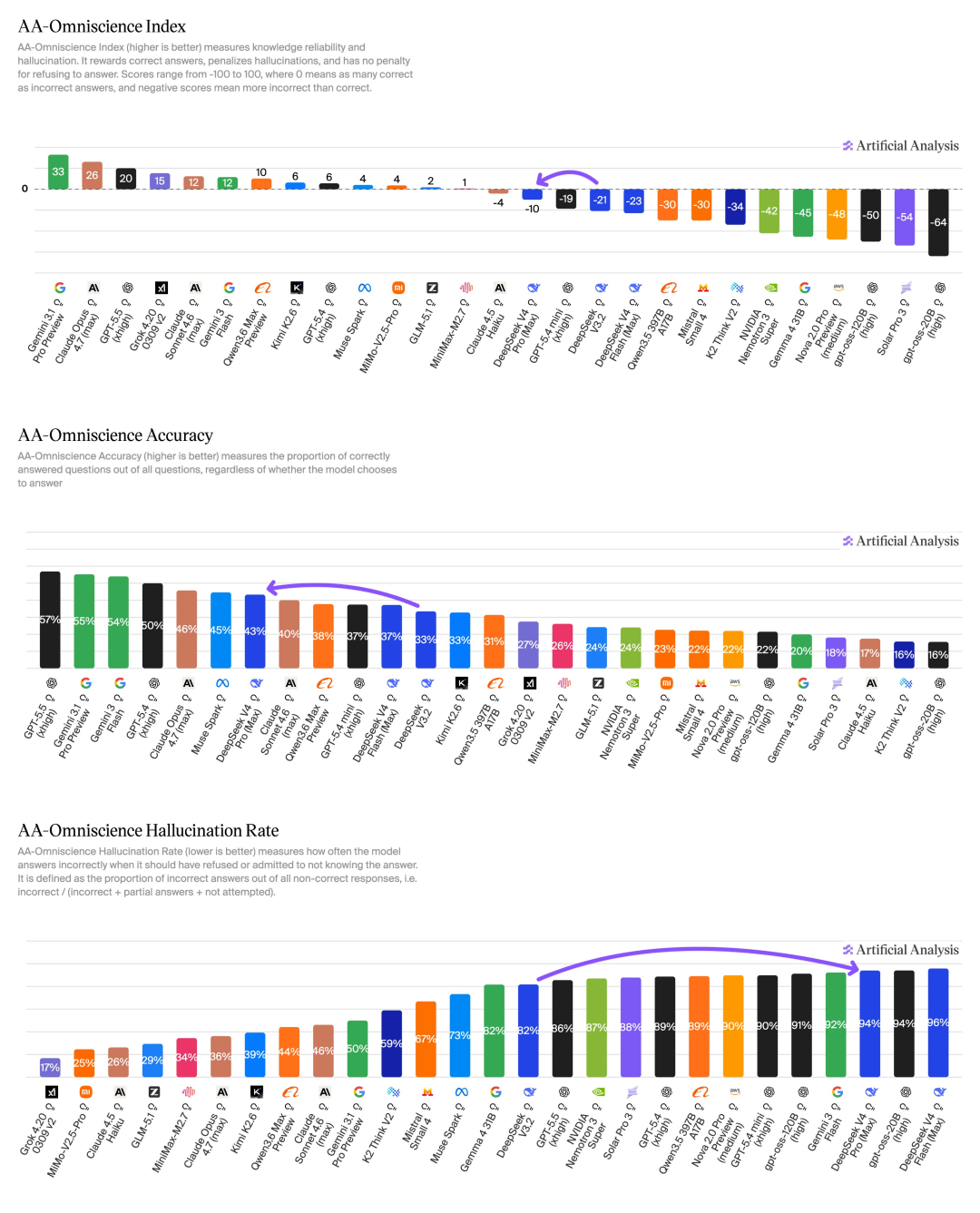
为什么咱们依然对DeepSeek充满敬意?
在此次V4的报告中,有东谈主看到了「训诲不稳」的苦闷,有东谈主看到了「幻觉严重」的短板。
但在咱们看来,这份报告最动东谈主的方位在于透明。
他们勇于承认硬件适配阵痛,勇于透露那些看似「补丁」的处理决策,更勇于展示我方何如用最硬核的工程能力,在几十万个沙箱里少许点磨出Agent的灵魂。
从V3的Multi-head Latent Attention到V4的OPD蒸馏和DSec沙箱,DeepSeek正在用一种近乎过火的「工程见解」,探索着大模子通往AGI的另一条旅途——
要是架构还没好意思满,那就用工程把墙砌厚;要是算力不够低廉,那就用算法把律例榨干。
DeepSeek-V4也许不是最好意思满的结尾AG真人国际厅(中国)官网,但它系数是当今最真实的、最充满活力的「中国AI现场」。
6686体育官方网站入口